导语
机器学习(Machine learning,ML)技术在代谢组学领域中的应用对推动代谢组学研究的发展功不可没。随着质谱设备的灵敏度越来越高,非靶向特征的数量级会成倍增加,使用ML方法,例如主成分分析(PCA)、线性判别分析(LDA)和自动编码器等,能够更轻松地展现样本的全局特征。ML不止局限于生物信息数据分析,前端数据的处理(如质谱的峰对齐和质谱中的自动靶向注释),ML也可用于疾病风险筛查和早期诊断的研究,尤其在肿瘤、心血管疾病、代谢类疾病等遗传与环境联合作用的复杂疾病研究领域。ML作为处理大量数据、构建研究模型的强有力工具获得广泛的应用。脉图健康将不定期推出关于ML相关知识的介绍,欢迎大家持续关注。
主成分分析(PCA)
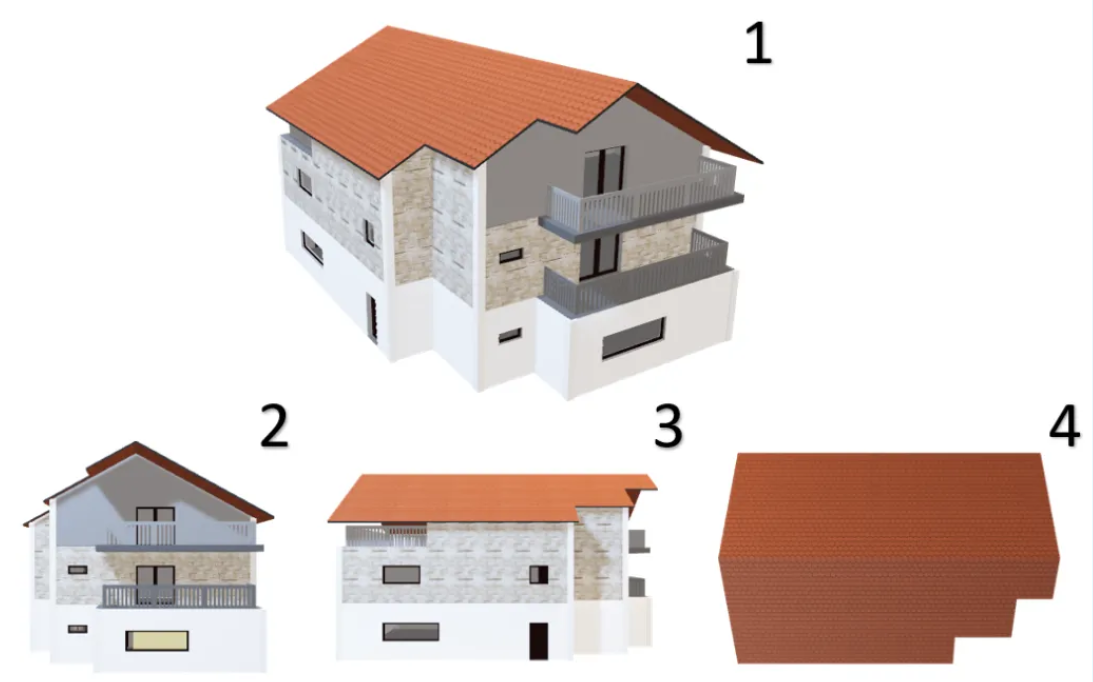
主成分分析(PCA)是最常见的代谢组学分析方法, 它利用正交变换(Orthogonal transformation)来对一系列可能相关的变量的观测值进行线性变换(Lineartransformation),从而投影为一系列线性不相关变量的值,即主成分(Principal components)。其中,这一数据的任何投影的第一大方差在第一个坐标(称为第一主成分或PC1)上,第二大方差在第二个坐标(第二主成分或PC2)上,依次类推。简单来说,该方法就是通过将高维度特征进行降维处理,从而达到展现数据主要成分的目的。如下图所示:图中第2、3和4三种平面展现的是房屋的部分特征,其中任意一张图皆不能完全显现房屋全貌,为了能在平面上展现房屋的主要全貌(图1),则可以相对全面的在平面图像里展现改房屋全貌,这是主成分分析的核心思想。图1 ( 模板来源:https://templates.office.com/en-us/fabrikamresidences-the-ultimate-in-modern-livingtm16411224)
偏最小二乘回归(PLS)
主成分分析法(PCA)的局限性是用以解释X的最大变化的旋转和降维并不能保证产生可预测y的潜在特征,换句话说,PCA的空间向量极易受到高权重响应变量的影响,低权重响应向量则在整体主成分中作用微乎甚微。因此更加高阶的监督学习方 法, 如偏最小二乘回归(Partial least square regression,PLS)、尤其是适用于处理离散变量的PLS-DA ( PLS-DiscriminantAnalysis,即判别分析)常常被用来处理更加复杂的特征区分。PLS分析的基本目标是将数据投影到潜在变量空间中,以使特征空间X和响应Y之间的协方差最大化,这样允许在自变量存在严重多重相关性(Multicollinearity)的条件下同样可以进行回归建模。
PCA和PLS-DA分析是代谢组学研究中常见的分析方法。利用PCA技术和PLS/PLS-DA分析技术,能够帮助研究者判断数据的质量,发现样本组间差异、寻找差异代谢物及候选分子标记物。
本期开启了小编的机器学习(ML)代谢组学之旅,未来小编将与脉图的技术专家一起带来更多的ML技术知识分享给感兴趣的小伙伴们!